Many resilient monitoring systems will automatically resolve a problem without any human interaction required. Paging users for incidents that could auto-resolve creates unnecessary noise for your on-call users. To avoid this issue, you may want to set up a waiting room. This article describes the process of setting up a waiting room escalation policy that will temporarily hold an incident for a configurable time period to allow for an automated resolution to an issue. When this action takes place, the incident is then automatically closed in VictorOps and on-call users will not be paged. If the incident remains open longer than the chosen interval, it is then routed to the responsible team/escalation policy as a triggered alert.
Please note: the Rules Engine section of this configuration requires a Full-Stack level of service.
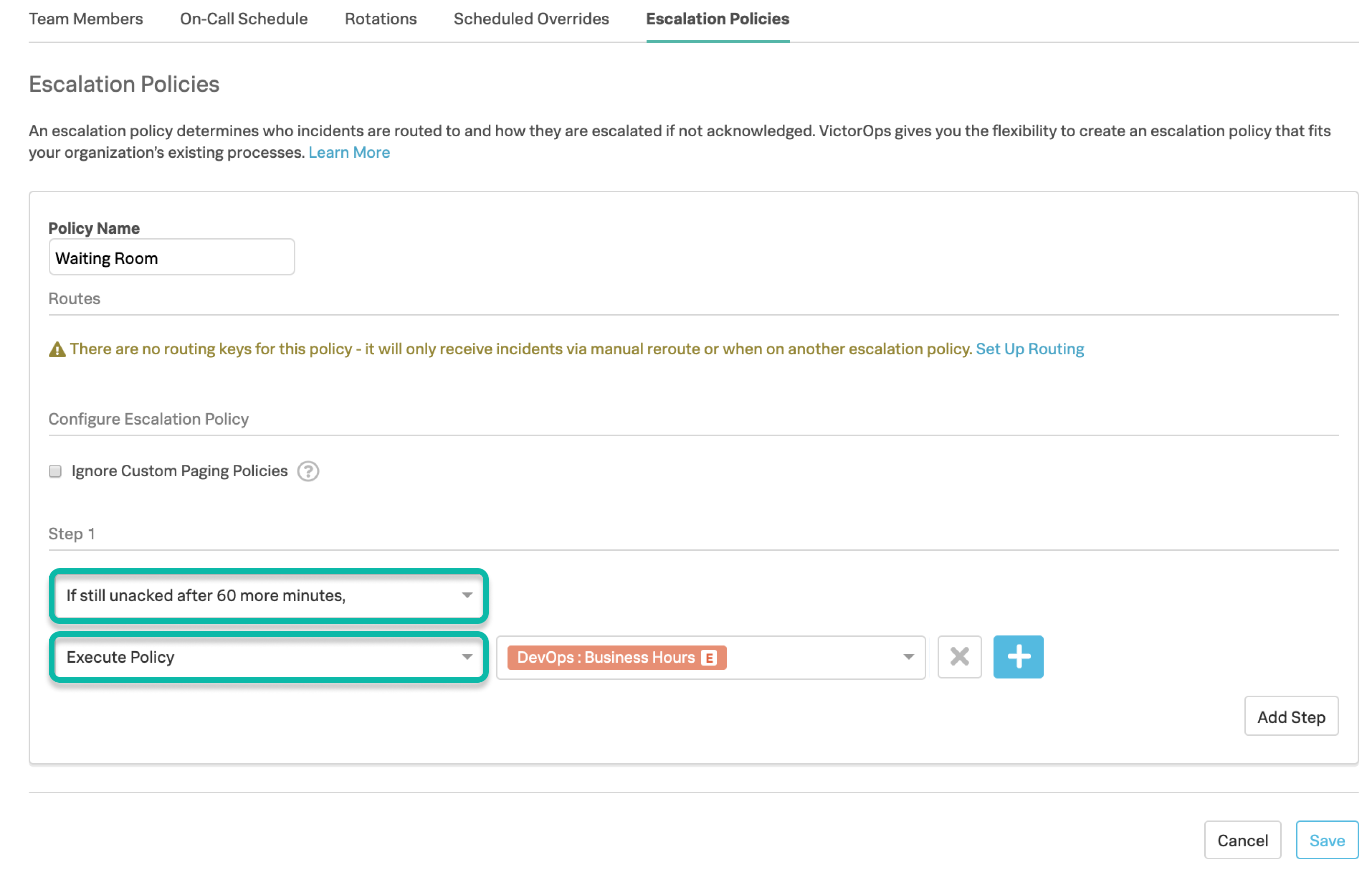
Create a new Escalation Policy
Navigate to the Team in need of a waiting room Escalation Policy. Click Escalation Policies >> Add Escalation Policy.
Set up the Escalation Policy
Click the drop-down for Immediately, and choose a time interval to delay alerts that are sent to this team’s Waiting Room Escalation Policy.
For the escalation type, choose Execute Policy and then choose the policy from the team that will be responsible for these incidents should they fail to auto-resolve within the configured time delay.
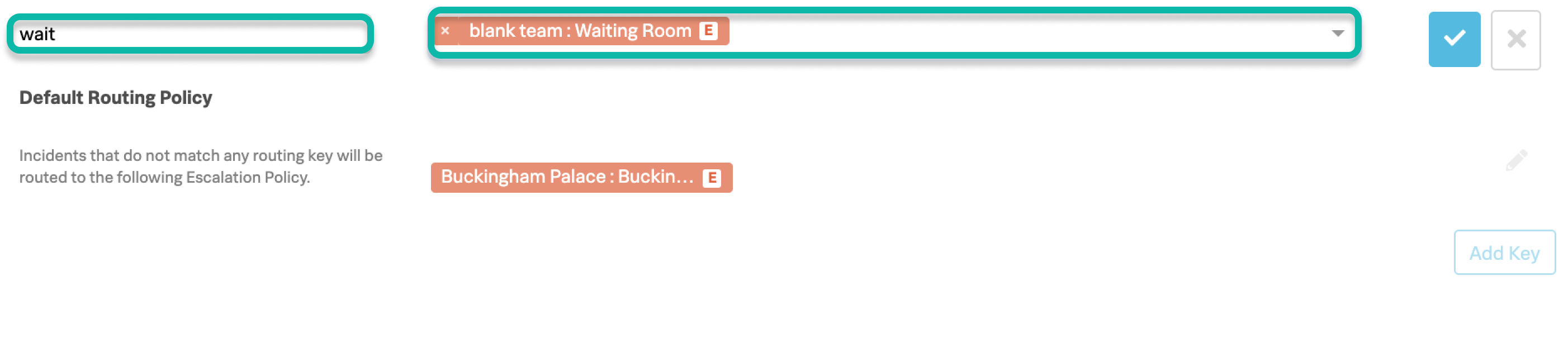
Create a Routing Key
Navigate to Settings >>> Routing Keys.
Select Add Key, give the new routing key a name and choose the waiting room team you’ve just created.
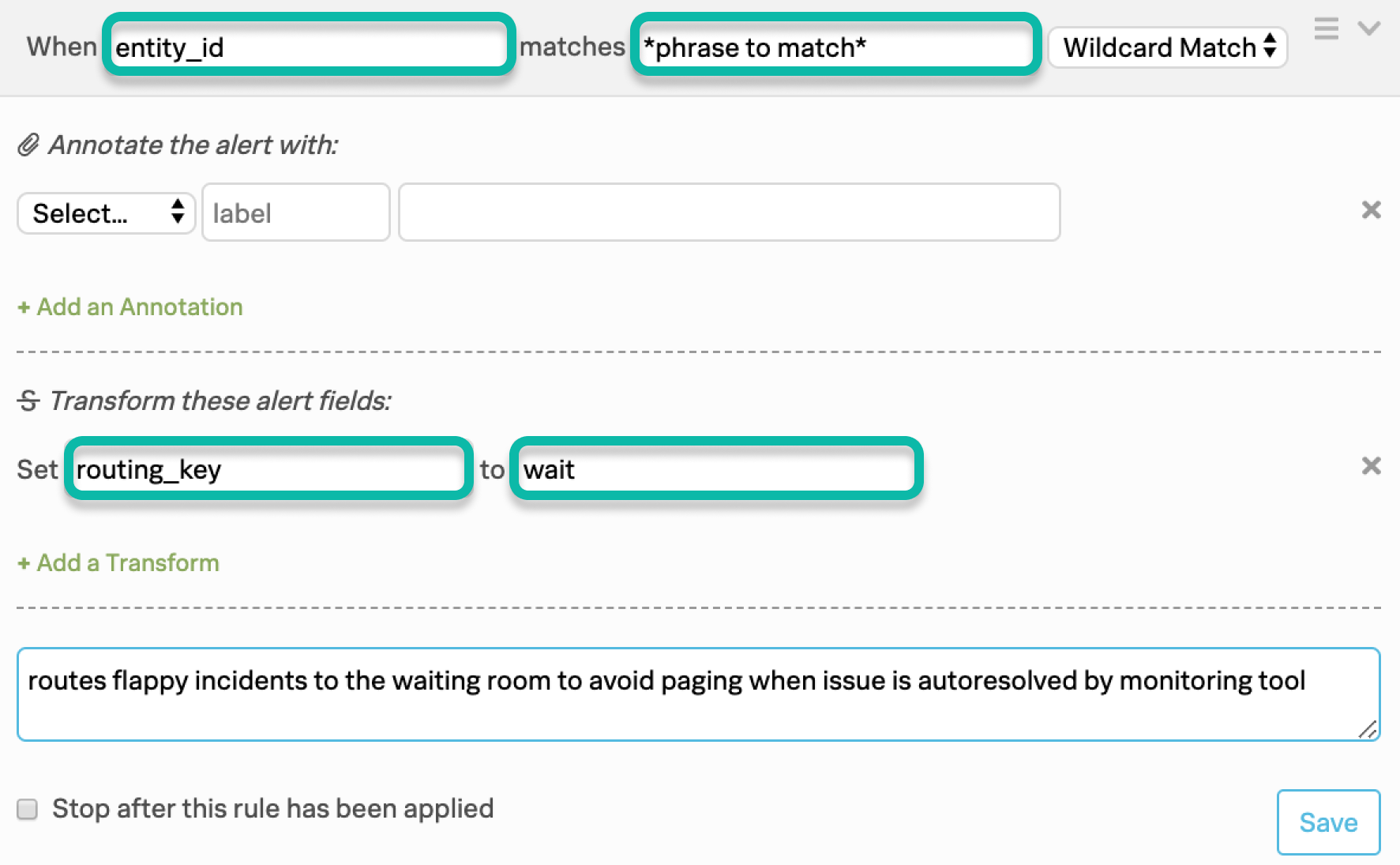
Set up a Rules Engine rule to route these incidents to the Waiting Room
Navigate to Settings >>> Alert Rules Engine, and then choose Add a Rule. In the following example, we’ve configured our rule to match the entity_id field to a wildcard phrase within variable of the entity_id field. Any incoming alert that has this matching condition will be routed to the waiting room escalation policy. This way you limit the scope of the matching condition to these issues only, without affecting an on-call team’s ability to be paged immediately in the event of an urgent issue. For more information on using the Rules Engine click HERE.
If you have a variety of incidents that require this approach, and multiple teams/escalation policies that will be responsible, you will need to set up a unique waiting room escalation policy (with its own routing_key) for each of those teams’ policies. For example, “Ops Waiting Room” (escalation policy points to Ops team), and “SRE Waiting Room” (escalation points to SRE team), etc.